3. Development in BASE¶
You can find a video overview of this section here.
3.1. Base Tables - The Design¶
This section, I’ll be discussing some of the BASE layer implementations, in preparation of our data mart.
However, what is a BASE layer?
BASE layer is the intial landing area for our Data Warehours modeling procedure for our Data Nart. It’s the “raw” layer for ingesting data, in its own purity.
For my own preferences and adoption of Kimball Methodology, this layer includes the following implementations:
Data Type (Explicity) Definitions
Data Cleaning
Column renaming [Optional, and can be in STAGE Layer]
JSON Unpacking (Feature in Snowflake)
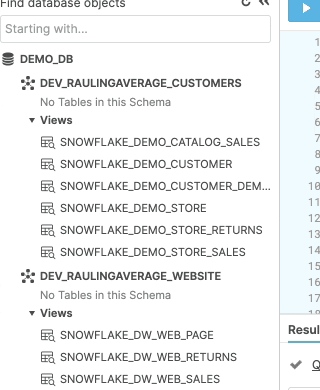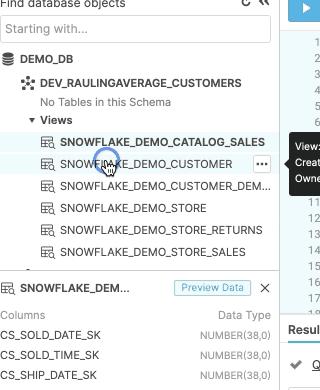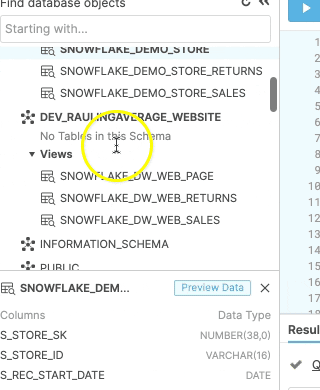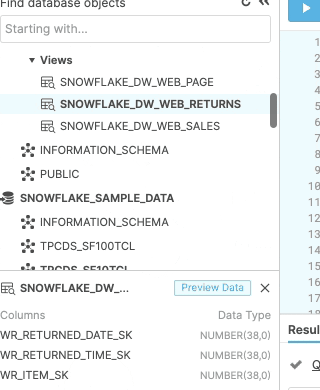
Here’s a visual example, with a subsequent breakdown:
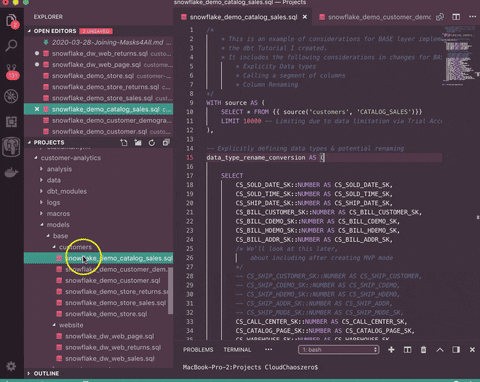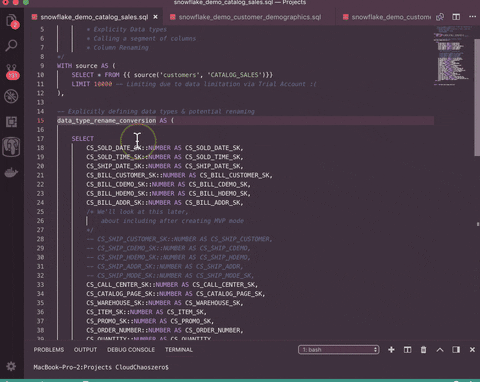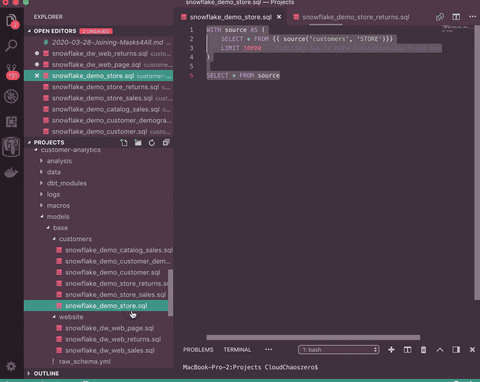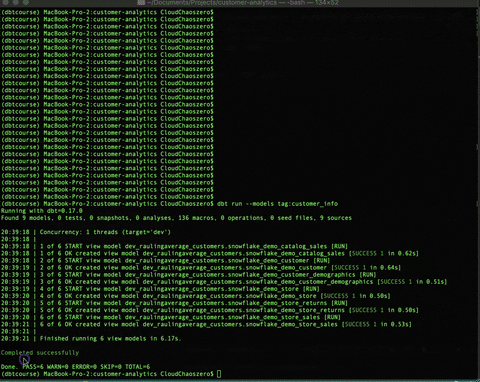
dbt run --models tag:website_info # As well
dbt run --models tag:customer_info
Tags are implemented in the raw_schema.yml file
3.2. Base Tables - The Implementation¶
3.2.1. Explicitly Defining Data Types¶
Depending how your first step of your ELT pipeline, Extraction process, you may have some displeasing storage inefficiencies that could affect either timing or costs in your data warehouse.
For example, we use Python to push data through Snowflake custom API calls. This data push sends all field’s data types as VARCHAR(XXXXXXXX) in Snowflake.
This can be detrimental in subsequent queries, transformations, or aggregations due to storage size allowed to the fields. With explicit data type conversions, we avoid these long term issues in our data warehouse.
For example, the following does an explicit data type conversion to NUMBER, assuming columns are VARCHAR(XXXXXXXX) type.
WITH source AS (
SELECT * FROM {{ source('customers', 'CATALOG_SALES')}}
LIMIT 10000 -- Limiting due to data limitation via Trial Account :(
),
-- Explicitly defining data types & potential renaming
data_type_rename_conversion AS (
SELECT
CS_SOLD_DATE_SK::NUMBER AS CS_SOLD_DATE_SK,
CS_SOLD_TIME_SK::NUMBER AS CS_SOLD_TIME_SK,
CS_SHIP_DATE_SK::NUMBER AS CS_SHIP_DATE_SK,
CS_BILL_CUSTOMER_SK::NUMBER AS CS_BILL_CUSTOMER_S
...
Note: Explicitly defining data types is also useful in tests around schemas, which dbt conveniently offers. We’ll talk about that in a later section. :)
3.2.2. Data Cleaning¶
There are some cases where your data comes in improperly. In the BASE layer, you’d want to proceed with some data cleaning operations such as:
Removing HTML characters
Dealing with NAN, N/A, or Null values
CASE WHENNNN tho
Defining Time Zones
Language Translation
and more!
I do not have any defined examples in this example, but this is some items to acknowledge.
Reader whispers…Why?
The above items could have impact into business reporting for aggregated calculations or summarizations
E.g.
Tabular data with field descriptions
Usage Events of when dates occurred
3.2.3. Column Renaming [Optional]¶
Imagine this, raw data landing into your data warehosue like this:
id |
label_0 |
|
|---|---|---|
1/1/1900 |
fake.email@aolo.com |
Impression |
1/1/1900 |
real.email@goog1e.com |
Click |
What does that all mean? What?
What’s worse, what happens if you’re trying to create a Data Catalog around these fields? Visually, displeasing.
Renaming our columns into human readable formats, or close to it, allows us to clearly understand what we are querying, and focus more on future objectives around that.
With some clean up, does this look better?
event_date |
user_email |
event_action |
|---|---|---|
1/1/1900 |
fake.email@aolo.com |
Impression |
1/1/1900 |
real.email@goog1e.com |
Click |
3.2.4. Json Unpacking [Snowflake, Optional]¶
Optionally, Snowflake has a cool feature to unpack JSON objects to tabular formats
This is not a sponsorship for Snowflake, just something really cool I use. You can find out more about JSON unpacking (Querying Semi-structured data) here.
With all that being said, and executing the aforementioned dbt commands……
dbt run --models tag:website_info # Materializing, as well
dbt run --models tag:customer_info
we have our tables in our Data Warehouse! :D